
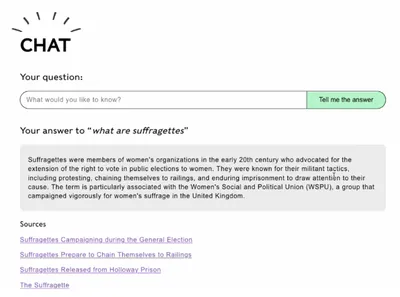
London Museum's Conversational Search
Hi folks, this week London Museum launched Clio 1.0, a new Conversational Search agent on our website. It’s an experiment to help users explore our collections and stories more intuitively, using natural language. Find out all about it below.
Conversational Search Part 1: The Journey
Following the rollout of our first raft of website AI initiatives which launched in 2024, we’ve seen significant increases in audience reach and engagement - up to up by 500% more visits to our collections online YoY and a GA4 engagement score is tottering around 62% vs. the culture sector average of 47%. So in December 2025 we began an experiment to deliver Clio 1.0, a Conversational Search function on the website. Why? I hear you ask. Because our ambition is to make our collections and stories as accessible as they can be to people everywhere. In particular we want to break down the barriers to exploration and engagement for non-specialists and people who might think museums are not for them.
So what is Conversational Search and what are its advantages over conventional search?
Well, by now most of us will have encountered chat agents like ChatGPT, Claude and Google Gemini. This approach to search allows users to ask questions in a natural language way so it’s more intuitive to use. Rather than being signposted to a list of links you get the answer to your query in paragraphs drawing together information from multiple sources and presenting it holistically in one place. So it’s also a more efficient way to find information. These AI chat services can also retain context from your previous questions to improve the quality of its answers to your follow up questions. In this way it supports back-and-forth dialogue so it’s also more engaging for the user.
But who cares? Well, maybe you, because you’re reading this article. And I certainly do! I’m irritated that people so often need a pre-existing level of knowledge about a museum collection before they can usefully engage with its conventional collections search. Conversational Search is perhaps a difficult concept to explain in abstract terms, you really just need to use it to understand the benefits. But I’ve always seen it as an essential part of our innovation roadmap and a stepping stone to what comes next.
The discovery phase
We started our journey by formulating some hypotheses and testing them through experiments. The goal of our experiment is firstly to validate we're actually creating something of value for users without replicating the existing collections search functionality. And then, with the constantly evolving technologies, to make decisions that limit the risks within the project.

Supported by our trio of talented partner agencies Torchbox, Knowledge Integration and Sun Dive Networks, we committed to working in a fast and iterative way, influenced by the data but as ever user experience focused. We assessed our backlog and overall aims against four criteria: desirability > viability > feasibility > responsibility. In the spirit of this we prototyped, early, quick and a little bit dirty and the results were very encouraging.
The first decisions we had to make were mostly about UX and UI. Where should a Conversational Search best sit within a website to be most visible and make most sense to users? The options as we saw them were
- Within the collections landing page, alongside the conventional collections search
- Within the site search overlay and the results page
- At individual page level
We decided that page level made the most sense as the first interaction for many users would probably be led by what they were looking at. But also given that a high proportion of our traffic comes from organic search and lands deep inside the site. So you’ll see the chat on all collections object pages, London Stories and blog pages. We’ll monitor how people use it during this first proof of concept to decide if it should also have a presence parallel to the conventional collections search.
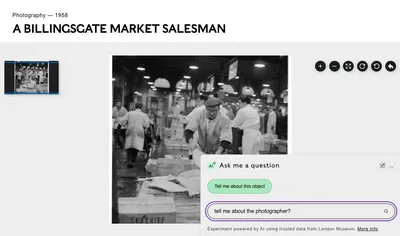
Are there limitations?
Yes absolutely, but we think the pros outweigh the cons.
Conversational Search tools often summarise or interpret collection data using natural language. That means dates, titles, or materials might be simplified or rounded. While you can trust that London Museum’s collections data is credible, it may be incomplete in some cases. Clio will only be able to give you an answer if it can find the data it needs.
The chat only uses London Museum’s trusted data to answer questions. This means that if other information exists somewhere online outside London Museum’s data but relating to your search query this won’t be included in our chat answers.
We’re training Clio 1.0 to use appropriate language terms based on our inclusive standards, but we are aware that offensive language and outdated terminology exist in our older records. As a result it may occasionally surface terms we no longer find acceptable. Moving forwards we aim to standardise our language, making conscious choices about the terms we will and won't use.
Find out more about our inclusive language approach here.
The quality of the chat will get better over time and with more usage. As the AI technology is improving daily and as we continue to train it based on how users interact with it.
What it can’t do?
If you ask it an existential question like: ‘What’s the point in museums?’ It’s likely to give you an existential answer! You can interpret this as you choose, it will not necessarily represent the views of London Museum.
It can’t show you image results in the chat window - for example if you asked ‘Show me all your paintings of the Thames’, but it will be able to signpost you to key pages to see the images. The reason we’ve chosen not to display images results is because we want to limit the environmental impact of the search and displaying images in this way uses lots of data.
No doubt there will be some people who will try to get it to produce contentious answers. We’ve done our best to train Clio how to handle these kinds of queries, but each case will be unique and we will learn and refine it with experience.
Are we killing the planet though?
Limiting the environmental impact is important to us so we wanted to explore further how best to do this. The museum’s policy is to prioritise AI solutions that minimise energy consumption and environmental impact, contributing to our wider sustainability goals.
Currently, we use two AI services to deliver the Clio 1.0 Conversational Search experience:
- OpenAI’s text-embedding-3-small model - to create embeddings, which are vector representations of our collection's data. This is a lightweight, task-specific model rather than a general-purpose language model.
- Anthropic’s Claude Haiku 3.5 model - which generates the conversational response based on data returned by these embeddings. The Haikus are the smallest and fastest models in Anthropic's Claude family. We have chosen not to use the multimodal capabilities to process rich media such as images, audio, and video. Clio only processes text queries making it more efficient. Although the model is trained on a broad dataset, we're just restricting the responses by only providing museum-specific data as context. All this can help to reduce the carbon footprint per task.
To put things in perspective
A single Conversational Search query using a small to medium-sized language model like Claude Haiku, typically uses 0.05 to 0.2 watt-hours (Wh).This includes the energy used to run the AI model on a data center GPU, excluding your device. One conversational AI query uses about 100 – 600x more energy than a traditional Google search. So if you ask 500 – 1,000 queries, that’s about the same energy as boiling one kettle of water.
More about Anthropic's commitment to responsible AI.
Conversational Search Part 2: Under The Bonnet
Choosing an LLM & prototyping
Early on we identified a shortlist of potential large language models (LLMs) to work with. It was important to find the most efficient prototype set up. A structure that would allow us to switch between the models in our staging environment, test and compare quality and performance.
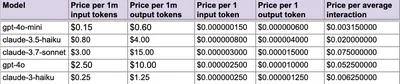
For our purposes, we felt Anthropic’s Claude models were the best performers in terms of reasoning, roundedness of answer and tone of voice. Then the task was to compare the best Anthropic’s models; Claude Sonnet 3.7 had just been released and we also compared the two smaller models Claude Haiku 3 and 3.5. Sonnet was slicker and more powerful out of the box and offered more configuration capability, but the Haiku models performed surprisingly well with extra prompt engineering.
Ongoing running costs are a major consideration for the experiment. Every piece of text (input + output) is broken down into tokens and costs are calculated per 1,000 tokens. We calculated some estimates based on varying volumes of usage - the cost difference between Sonnet and the Haikus was considerable. We went with Haiku 3.5 which was first released in July 2024. Fast forward to July 2025, more advanced models Claude Sonnet 4 and now Claude Opus 4 are available which should in turn see the prices of older models come down.
Is it cheaper to run open source LLMs ?
Yes, using open-source large language models (LLMs) can be significantly cheaper than commercial LLMs like Claude. However, the total cost depends on how you deploy them (cloud vs. local), what tasks you run, and whether you need infrastructure, scaling, or support. There are no API costs, so you don’t pay per token, and self-hosting is possible with supporting IT, they can run locally or on your own cloud servers.
Just as we kicked off our prototyping, the Chinese market disrupter model DeepSeek started to get lots of media attention, primarily about its efficiency and low energy consumption compared to other commercial models, but also about privacy concerns and China’s data policies. With a self-hosted version the privacy risks are mitigated, and you have more technical flexibility. If you run DeepSeek on your own server, you skip the energy-heavy cloud servers used by ChatGPT or Claude. This reduces the energy cost of sending data back and forth across the internet.
Weighing up the pros and cons though, our approach has been to experiment first within the structure of a commercial product and learn what we need so that we can potentially explore a self-hosted alternative in the next phase.
Refining the models
So refining the way these models interpret your data and structure their answers is a potentially bottomless pit of tweaking. Things can get a bit whack-a-mole. A small adjustment in one place can cause a major impact in quality elsewhere. Here are a few key things to understand.
The difference between ‘prompt engineering’ and ‘prompt configuration’?
- Prompt Engineering is the discipline of designing effective prompts to get the best quality responses in terms of accuracy, logic, tone of voice and copy structure. This is where you would add things like guidance around terminology. Tweaks to prompts can become very nuanced so this is handled by our in-house Products team who are close to the museum’s sensitivities rather than by our developers.
Top tip: for refining your prompts further. Ask ChatGPT to help you with this - it knows how to write good prompts!
Examples:
‘Structure answers in short paragraphs. Only use bullets where relevant’
‘Use British spelling’
‘Don’t link to external websites’ - Prompt Configuration is the technical setup and parameters that guide how the model behaves. This is handled in settings and system-level instructions. It includes things like setting token limits and temperature - the setting that controls how creative or predictable the model’s responses are. This is handled by our developers and plays a key role in reducing the risk of hallucinations.
- A similarity index powered by Elastic Search is used to compare and find connections between vectors and embeddings. It works by assigning a numerical score that measures how alike two pieces of data are and you can then specify how close you want the vectors to be. During our testing we hit a problem computer scientists call ‘reversal curse’ - this is when the LLM doesn’t recognise the same name when its expressed first name > last name vs. last name > first name. This is because it converts the words into vectors and so if first name = 1 and last name = 2 then Trish Thomas has the vector 12 and Thomas Trish has the vector 21. The machine reads these as different people. And of course our collections database is full of instances where names are written both ways. In v 2.0, we need to counter this. So alongside embeddings, we’ll use a knowledge graph - in this case the structured ‘people’ ‘authority’ in our collections database. This provides us with a more deterministic lookup to sit alongside the fuzzy logic of the vectors approach.
More about ‘reversal curse’ here if you want to go deep.
- Continuous improvement - we store the anonymised chat data for up to 90 days and analyse it regularly in order to help us refine the way Clio 1.0 works.

Perfection vs. value
Of course comprehensive testing is hugely important. We put Clio 1.0 through three rounds of user testing, with both groups of curatorial and collections data specialists and non-specialists in parallel. We made refinements to the prompts, UX and UI each time based on their feedback. The testing was also helpful in identifying the kinds of queries that are just best carried out using a conventional collections search and agreeing therefore that there was little value trying to replicate that technical development in a chatbot. Typically this includes queries like searching for a specific object using its unique collections ID or asking questions like ‘How many pilgrim badges exist in the collection?’. For me one of the biggest wins was hearing a curator who was trying to do some research using our rigid collections management system say how much easier it was to find collections information using the free-flowing chat!
Dates were also an area of complexity because they can be expressed in so many different ways within our collections database. Say an object originates from the period 1780-1799, that might be expressed as from the Hanoverian period (1714 to 1837) or from the Georgian period (1714 to 1830) or from the 18th century or Eighteenth century. It will take time to train the model to understand that all of these mean the same thing.
Along the way we also had a great conversation with Canadian-based AI developer Jonathan Talmi who set the sector alight earlier this year when he released his Living Museum project, an AI-driven conversational web app powered by the British Museum’s online collection. He (perhaps naively), wasn’t expecting the enormous backlash and outrage it caused! Because and I quote he had: “unwittingly violated academic norms, advanced a colonialist narrative, and worst of all, shoved AI where it didn't belong.” All that was true but of course, but it did somewhat overshadow the raw technical brilliance of his early proof of concept. You can read more about how his project came about and the public response in his blog here.
https://www.talms.me/posts/living-museum/
https://www.livingmuseum.app/explore
As I write this I'm also conscious of the impact of changes in the wider tech landscape particularly in terms of referral traffic from organic search since Google made its core update in spring. With the rollout of Google’s expanded AI overviews (powered by Gemini), surfacing longer answers in the interface, we're seeing increasing zero-click searches, especially for non-branded keywords - if people get a fuller answer in Gemini the need to click through to your website is reduced.
Our silver bullet remains the credibility of our source data which is something that Gemini can’t guarantee as it casts its net far and wide across the internet for answers.
So what next?
Well it’s out there now, so eager to see how people use it (or don’t use it), so we can learn. As with all experiments, it won’t be perfect and there are risks but it's all a learning curve. I hope you enjoy using Clio 1.0 as much as we have and that it takes you on some voyages of unexpected discovery.
What could your team achieve with an AI co-investment?
We’re co-funding AI pilot projects for the GLAM sector, with up to £15k in match funding, through our Employee Ownership Trust.
More
-

What could your team achieve with an AI co-investment?
Lisa Ballam Head of Marketing, Trustee Director
-

Eight considerations before launching a public-facing AI tool
Mark Boyle Client Partner (Public Sector)
- See more posts
